Your Turnitin guidance is moving!
We’re migrating our content to a new guides site. We plan to fully launch this new site in July. We are making changes to our structure that will help with discoverability and content searching. You can preview the new site now. To help you get up to speed with the new guidance structure, please visit our orientation page .
什么是相似性?
Turnitin 不会检查作业中是否存在剽窃。我们将改为针对我们的数据库来检查学生的作业,如果存在学生的作业与我们的其中一个来源相似或匹配的情况,则会对此进行标记,以供您复审。我们的数据库包含数百万个网页:来自互联网的当前和存档内容、学生以往提交到 Turnitin 的作业的存储库,以及由几千份期刊、杂志和出版物组成的文档集合。
作业与我们的部分数据库相匹配再自然不过。如果学生使用引述并正确进行了参考,则会出现我们将找到匹配的情况。相似性分数只是突出显示学生论文中的任何问题方面;然后,您可以将此用作调查工具,以便确定匹配是否可接受。
匹配和来源之间有何差异?
匹配
来源- 来源是找到特定匹配的位置。这可以是网页、学生论文或出版的杂志。来源在洞察面板中按数字列出,并且每个来源可能有多处匹配。选择其中一个来源将揭示如下信息:针对该特定来源找到的匹配数量,以及每处匹配在该网页、学生论文或杂志上的所在位置。
相似性分数范围
相似性报告提供在所提交论文中找到的匹配或高度相似文本的摘要。当相似性报告可供查看时,将可使用相似性分数百分比。尚未完成生成的相似性报告在“相似性”列中以灰显图标表示。不可用的报告可能尚未生成,或者作业设置可能将延迟生成报告。
已覆盖或已重新提交的论文整整 24 小时无法生成新的相似性报告。此延迟是自动的,并且允许在与先前草稿不匹配的情况下正确生成重新提交。
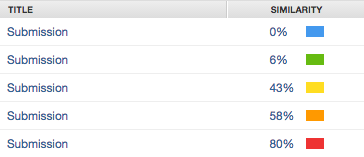
报告图标的颜色根据所发现的匹配或相似文本量来指示论文的相似性分数。百分比范围为 0% 到 100%。可能的相似性范围为:
- 蓝色:无匹配文本
- 绿色:1 个字到 24% 匹配文本
- 黄色:25-49% 匹配文本
- 橙色:50-74% 匹配文本
- 红色:75-100% 匹配文本
评分方案
示例 1:
学生过去可能已将论文提交到 Turnitin。如果他们在提交时已署名,那么在未排除细微匹配的情况下,他们的姓名完全有可能在其相似性报告中突出显示。
导师可以通过按字数排除来纠正此问题。在大多数情况下,排除 5 个字应该可以放心排除学生在其相似性报告中突出显示其姓名的情况。
示例 2:
学生可能已使用 Turnitin 提交同一论文的草稿,意味着其最终草稿的得分为 100%。
导师可能知道其学生已多次提交,他们可以通过从相似性报告中排除学生的先前提交来纠正此问题。
示例 3:
一名学生由于对其所涵盖的主题缺乏了解,在其论文中粘贴并复制了大量文本。其相似性分数为 20%。相比之下,另一名学生对同一作业具备扎实的知识基础,知道如何从多个来源收集信息以正确引述和参考,其相似性分数为 22%。系统将显示两名学生均有与我们的数据库相匹配的内容。但是,其中一名学生直接从网站进行复制,而另一名学生则提供了正确来源的引述。
导师可以选择从相似性报告中排除引述,以在适用情况下降低相似性分数。
示例 4:
一名学生设法获取了另一名学生的论文副本。他们在 12 月 15 日将此论文提交到 Turnitin,得到相似性分数 25%。最初写作该论文的学生一周后将论文提交到 Turnitin,得到相似性分数 100%。
在此情况下,重新生成已剽窃的学生的相似性报告将会立即识别串通舞弊行为,从而使您能够依照院校规章进行处理。
示例 5:
学生向 Turnitin 提交了一份定量研究,包括论文主题所要求的大量引述和各种书目。该学生的相似性分数为 53%:这超过了其院校设定的可接受分数。
如果已从相似性报告中排除引述和书目,则本可避免此问题。
Was this page helpful?
We're sorry to hear that.
